WORLD-LEADING
OPTOELECTRONIC SIMULATION SOLUTIONS
Multi-GPU Parallel Acceleration · 10-100x Speed Improvement
High Precision Algorithm Verification · Completely Self-Controlled



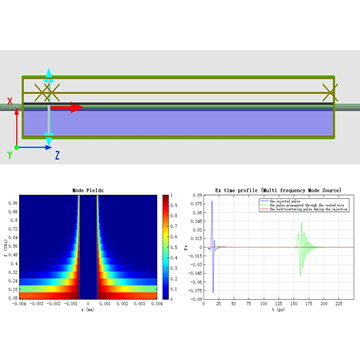
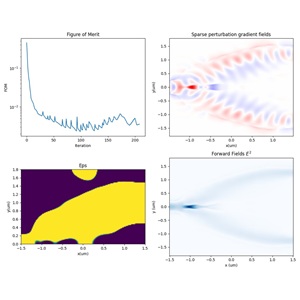
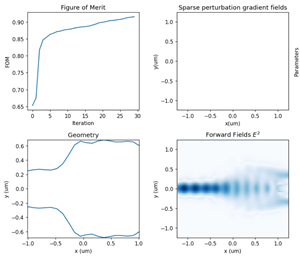
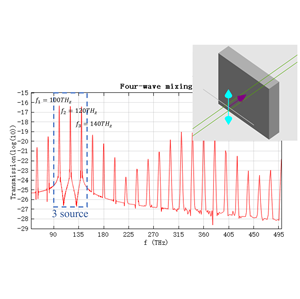


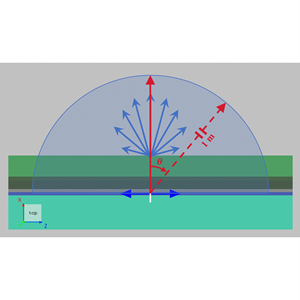
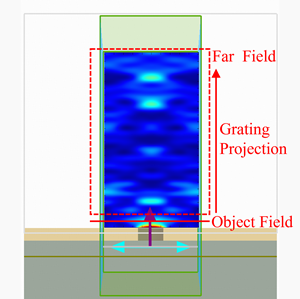
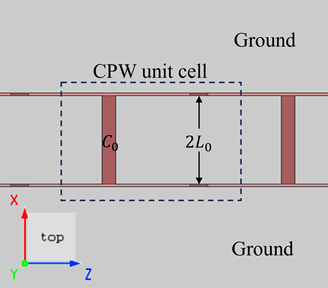

- New stack Script Commands: Rapid Calculation of Optical Response for Planar Multilayer Film Stacks
- New Assembly Group Feature
- New Conformal Variant CP‑EP0 Conformal Mesh Method
- Custom Time Signals for Light Sources via Script
OVERVIEW
Product Introduction
SimWorks Finite Difference Solutions is a powerful tool for the optoelectronic design community

CORE TECHNOLOGY & PERFORMANCE
Exceptional Performance
Integrating advanced numerical algorithms with GPU parallel computing to deliver industry-leading optical simulation solutions
Compared to CPU, a single GPU can achieve a speed improvement of over 10x, while multi-GPU configurations can deliver up to 100x performance improvement
Single computers generally support up to 8 GPUs, and CUDA-Aware multi-GPU parallel computing can exceed the limit of a single machine, enabling the full release of the cluster performance
Supports FP16 precision computing, ensuring accuracy while fully leveraging the performance of professional GPUs (NVIDIA Tesla), achieving at least 2x speed improvement compared to FP32
Rich Parallelization Methods
Supports MPI, CUDA, OpenMP, AVX, and AppleMetal parallel computing schemes, flexibly adapting to user hardware configurations and fully leveraging hardware performance capabilities
Computational Speed
Deep optimization of core numerical algorithms, with a speed leading in the industry
Computational Accuracy
Through the deep research of the algorithm principles, massive precision tests, and verification of all aspects of the computed results, the solver's accuracy is fully consistent
Single-GPU Performance Comparison
Cloud Elastic Compute
No need to purchase expensive local workstations, use cloud GPU clusters on demand, pay as you go
WHY CHOOSE SIMWORKS
Business Highlights
Flexible business model and excellent compatibility, making simulation work easier
Elastic Computing Power
Elastic Computing Power
Pay-as-you-go cloud computing model, no need to purchase expensive hardware, lower development cost
- Pay for the resources you use
- Register to get free plan, no need to pay
- Accelerate with high-performance GPU
ZERO MIGRATION COST
Seamless Migration
A premier FDTD simulation solution with familiar workflows and effortless adoption
- Rich software features
- Similar operation interface and job process
- Easy migration with script API
CROSS PLATFORM
Cross-Platform Support
Windows、Linux、macOS full-platform native support, work anytime, anywhere
- Windows 7+
- Linux distributions
- macOS 11+
CLOUD, LOCAL & ENTERPRISE
Flexible Deployment
Adapts to various scenarios, supporting cloud-based usage, local professional edition, and enterprise private deployment
- Cloud Client - Free, on-demand cloud computing resources
- Full Version - Local + cloud dual mode, professional-grade experience
- Enterprise Edition - Network isolation, multi-node parallel computing
KEY FEATURES
Solvers
Rich solver lineup, precisely addressing each challenge in the micro-nano optical field
FDTD
Finite Difference Time Domain SolverFDTD is a powerful tool to handle various micro-nano optoelectronic problems.
Learn MoreFDE
Finite Difference Eigenmode SolverFDE is a powerful tool for solving large-scale integrated planar optical waveguides, long-distance transmission devices, and various new fiber optic problems.
Learn MoreFDFD
Finite Difference Frequency Domain SolverFDFD is a powerful tool for analyzing the spectrum of resonant cavities and metal antennas.
Learn MoreEME
Eigenmode Expansion SolverEME is the method of choice for modeling complex waveguide systems in integrated photonic device development.
Learn MoreFDCharge
Finite Difference Charge Transport SolverFDCharge is a powerful tool to simulate the electrical behavior of semiconductor devices.
Learn MoreSOFTWARE CAPABILITIES
Technical Highlights
Advanced underlying technical architecture, providing solid support for efficient and accurate optical simulations
Excellence in GPU Acceleration
Supports multi-GPU parallel computing, achieving 10-100x performance improvement, significantly reducing simulation time.
Flexible Scripting and Rich API Support
Supports custom scripting to meet complex simulation needs; provides Python/MATLAB API for easy integration with external tools.
Comprehensive Inverse Design Support
Supports inverse design, enabling efficient and high-precision automated device design through mathematical optimization and physical simulation closed-loop iteration.
Efficient Optimization Scanning Functions
Provides parameter scanning, S matrix scanning, and optimization three-function modules. Supports custom parameters to quickly converge to local optima.
Rich Material Library and Custom Material Models
Built-in dielectric, dispersive, nonlinear, graphene, and discrete point materials, supporting custom material parameters and model fitting.
Comprehensive Post-processing and Analysis Tools
Provides analysis group functionality, including far-field calculation, band structure analysis, and photoluminescence calculation; built-in analysis library, allowing users to create custom analysis groups and reuse scripts.
SERVICES
Design & Simulation Services
In the modern technology industry, design and simulation are closely integrated. Predicting and evaluating performance during the design process to improve the efficiency of design optimization has become a fundamental part of the research and development workflow.
Leveraging its experience and technical capabilities in the optoelectronics industry, the SimWorks team uses its proprietary SimWorks simulation platform to provide customers with design, simulation, and performance optimization services—ranging from components to systems—thereby supporting customers’ R&D efforts. Based on the design requirements and specifications provided by customers, we can build digital models, complete design optimization, and deliver simulation reports. Our services cover passive devices, gratings, sensors, metalenses, and other related areas.
WHERE IT WORKS
Applications
It is widely used in cutting-edge research fields such as photonic crystals, metasurfaces, and nonlinear optics.