
计算资源
概述 #
本节是关于计算资源配置的介绍。
SimWorks 提供了灵活的计算资源配置选项,支持多种软件加速和并行计算技术,能够满足不同用户的仿真需求。SimWorks Finite Difference Solutions支持 Cloud 、 Local 和 Remote 三种资源模式,帮助用户充分利用现有计算资源。
在运行工程仿真前,用户可通过主界面选项卡中的 Resources 进入资源配置界面,根据实际需求灵活选择并设置计算资源。
- 云计算( Cloud ):基于商业公有云服务构建,支持高性能计算(HPC)和弹性云服务器(ECS),提供可按量使用的企业级算力。
- 本地加速( Local ):支持调用用户本地硬件资源,通过多线程 CPU 与多 GPU 并行计算,并结合 OpenMP 多线程技术与 AVX 指令集进一步加速计算,最大限度发挥自有硬件的性能。
- 远程并行( Remote ):支持连接并调度多节点计算资源,将计算任务分配至多台服务器。兼容 Open MPI、Intel MPI 以及 Microsoft MPI 多种并行计算架构,适用于大规模分布式仿真。
- Slurm集群( Slurm Cluster ):支持连接外部或者用户自行搭建的 Slurm 集群,可直接提交大规模仿真任务。提供共享文件夹映射,免去手动上传下载文件的步骤;在 Linux 系统上还可从本地直接提交任务,操作更便捷稳定。
上述资源模式构建在统一的高性能计算技术之上,其优异的仿真效率由以下核心加速技术驱动:
- CPU端:多级并行与向量化优化
在 x86 CPU 平台上,我们构建了“线程级+指令级”双重并行架构,充分发挥了每个计算节点的单机算力。
- 线程级并行:基于 OpenMP 标准实现任务划分与负载均衡。每个线程负责一个或多个空间子域的场量更新与边界交换,有效利用多核 CPU 的并行能力。
- 指令级并行:核心算法经向量化优化,全面支持 AVX2(256位)与 AVX512(512位)指令集。通过重构数据在内存中的布局,提升内存带宽利用率与单核计算吞吐量。
- GPU端:异构加速与多卡协同
针对GPU计算,我们采用设备特定后端分离的设计,采用 CUDA-aware MPI 等并行技术,为从本地多GPU到多节点GPU集群的应用场景提供了强大且可扩展的并行计算能力。
- NVIDIA CUDA后端:
- 本地多 GPU 协同:通过高度优化的内核函数及 CUDA-aware MPI ,实现多 GPU 间的高效通信,自动处理域分解、数据交换与同步过程。
- 多节点多 GPU 扩展:结合 MPI 技术,实现跨节点 GPU 集群的扩展。用户可利用 InfiniBand 等高速网络实现工业级超大规模仿真。
- Apple Metal后端:
- 针对 Apple Silicon(M系列芯片),利用 Metal 的命令缓冲与并发队列机制,实现 CPU-GPU 紧密协同,适合在桌面级 Mac 设备上进行快速仿真。
- 多节点分布式并行:灵活的MPI生态集成
此为远程并行模式的核心构成,旨在支持大规模仿真问题的求解。系统采用“域分解+消息传递”策略,天然适配分布式内存架构。
- 空间域被分为多个计算子域,每个MPI进程负责一个子域的计算任务。在支持 RDMA(如 InfiniBand)的网络环境中,可进一步降低通信延迟,提升并行效率。
- 支持多种主流 MPI 的实现版本:
- Intel MPI:英特尔专为 Intel 硬件平台开发并优化的 MPI ,提供低延迟、高带宽的通信能力。
- Open MPI:开源且可移植性强,在不同硬件配置下性能稳定,支持Linux、Mac系统。
- Microsoft MPI(MS-MPI):微软为 Windows 环境开发的 MPI ,便于企业用户基于现有IT基础设施快速部署。
综上,SimWorks的 FDTD 不仅是一个求解器,更是一个面向现代异构高性能计算架构的综合计算平台。无论用户使用单台工作站、企业级多GPU服务器,还是千核级计算集群,均可获得一致、高效且可扩展的仿真体验,为电磁、光子、天线及生物电磁等领域的前沿研究与工程设计提供坚实算力支持。
计算资源 #
本节是关于计算资源配置的介绍。
在运行工程仿真前,需要用户配置计算资源。在软件的 Home 选项卡中,用户可以按照以下方式打开计算资源配置窗口:
- SimWorks Cloud FDTD(SimWorks 有限差分云客户端)用户点击Cloud按钮;

- SimWorks FD Solutions(SimWorks 有限差分完整版客户端)用户点击同位置的Resource按钮。

资源配置页面如下,可以为FDTD、FDFD、FDE、FDCharge、EME五种求解器设置各自使用的计算资源,以及高级选项卡中的计算精度。该页面的按钮功能如下:
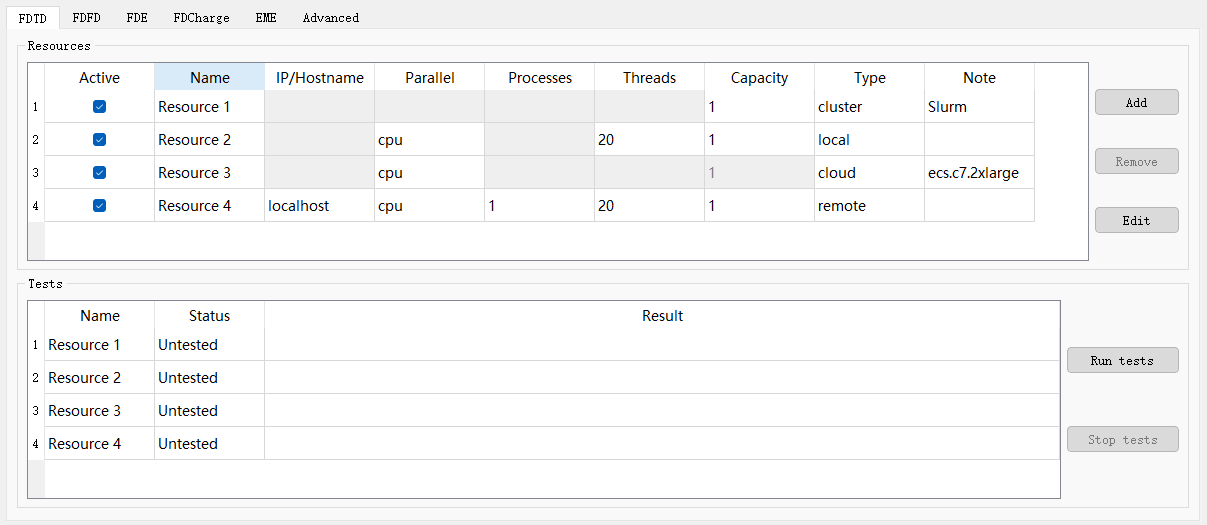
| Name | Description |
|---|---|
| Add | 添加一个新的计算资源; |
| Remove | 移除选中的计算资源; |
| Edit | 编辑选中的计算资源。 |
用户需要点击Edit进一步配置计算资源。需要注意的是,目前有四种计算资源可以进行设置:云计算(Cloud)、本地计算(Local)、远程计算(Remote)和 Slurm集群(Slurm Cluster) 。云客户端仅支持调用云计算资源(Cloud),而完整版客户端可同时支持四种计算资源。以下是对这四种计算资源配置的简要说明:

| Name | Description |
|---|---|
| Local | 使用用户本地计算机算力,不支持多机并行计算,SimWorks FD Solutions支持; |
| Remote | 可以选择多台计算机算力,支持多机并行计算,SimWorks FD Solutions支持; |
| Slurm Cluster | 可以连接外部或者用户自行搭建的 Slurm 集群,直接提交大规模仿真任务,SimWorks FD Solutions支持; |
| Cloud | 直接调用云计算资源,SimWorks Cloud FDTD与SimWorks FD Solutions均支持。 |
Cloud资源 #
SimWorks的Cloud资源依托阿里云、腾讯云等商业云平台构建,最高可使用64核 CPU 与8卡 NVIDIA A10 GPU 计算资源,为用户提供企业级算力支持。用户通过注册SimWorks账号即可实现即开即用,系统无需本地环境部署维护,也不依赖用户端设备性能,用户仅需网络连接即可实现跨地域实时进行仿真操作。针对工程数据传输环节,SimWorks依托商业云的安全防护体系与自有加密技术的双重保障,确保全流程数据安全。
资源类型 #
Cloud资源类型分为高性能计算(High Performance Computing, HPC)和弹性云服务器(Elastic Compute Service, ECS)。高性能计算中资源为共享资源,当多用户选择同一个资源进行仿真时,该资源将按需分配算力给用户。弹性云服务器则实现计算资源的即开即用和弹性伸缩,其中的资源为独享资源,用户的仿真任务可以使用该资源的全部算力。
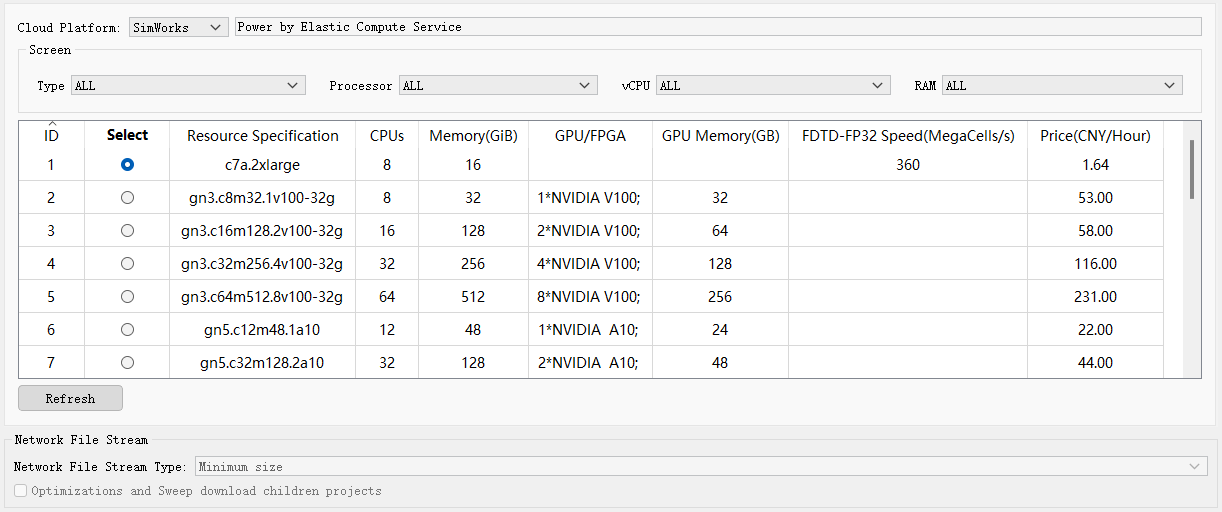
| Name | Description |
|---|---|
| ID | 资源的序号。 |
| Select | 用于选择资源的勾选框。 |
| Instance Specification | 资源的规格。 |
| CPUs | 资源的CPU核心数。 |
| Memory(GiB) | 资源的内存大小。 |
| Clock Speed(GHz) | 资源CPU核心的主频。 |
| GPU/FPGA | 资源的GPU/FPGA的类型。 |
| GPU Memory(GB) | 资源的显卡内存大小 |
| FDTD-FP 32 Speed (Megacells/s) | 资源的理论FDTD速度。 |
| Price(CNY/Hour) | 资源计算一小时的单价。 |
由于高性能计算中的资源是由云计算按需分配,可能会出现同一时间有大量仿真任务导致资源短缺的情况。用户可以点击refresh查看当前资源是否可用(资源变灰则不可用),避免因资源暂时不足而长时间排队等候。
网络文件流 #
网络文件流(Network File Stream Type)选项卡用于选择网络传输文件流的类型,默认为最小尺寸(Minimum size)。用户可以点击账户中的 History 按钮查看并下载仿真结果文件。

Local资源 #
Local资源基于本地计算资源运行,其性能上限直接受限于终端设备的硬件规格。针对对仿真效率有严苛要求的场景,建议通过升级CPU/GPU算力、增加内存容量等硬件优化手段提升运行效能。该模式适用于具备高频仿真需求且拥有高性能计算设备的用户选择。
Local资源设置 #
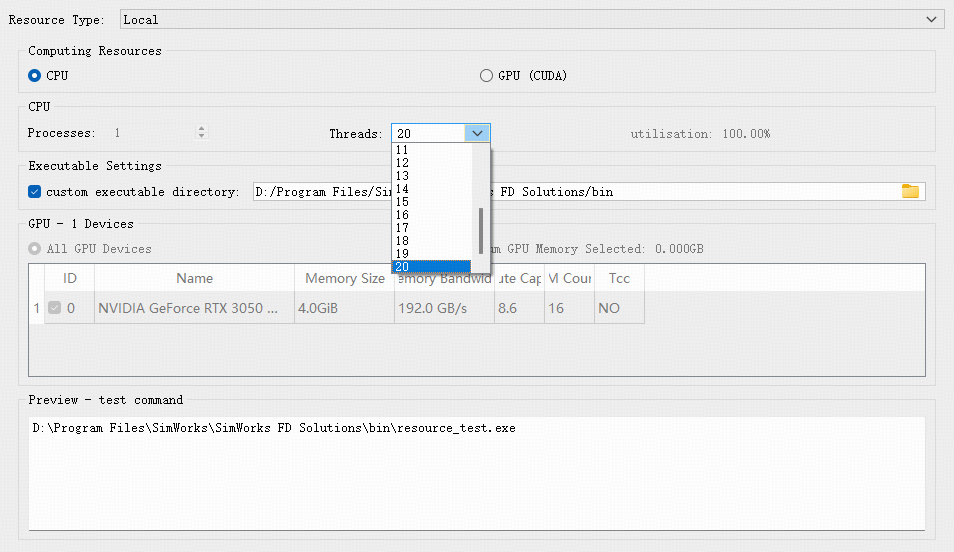
Local资源可选择本地CPU/GPU算力:CPU支持多线程并行计算,可设置线程数;GPU可勾选不同的GPU ID使用本地的GPU资源进行计算。
- CPU算力资源设置
- GPU算力资源设置
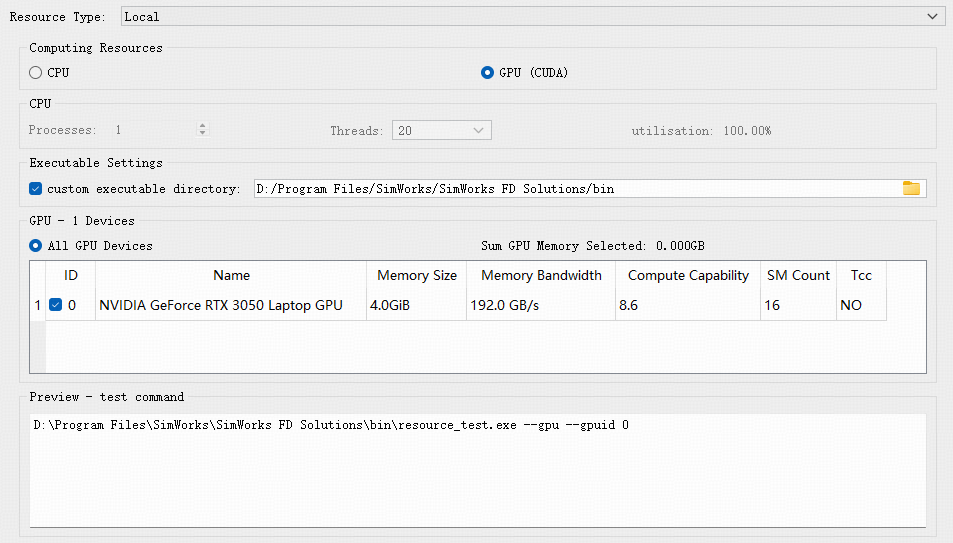
以上各选项意义如下:
| Name | Description | Example |
|---|---|---|
| Computing Resources | 算力类型选择,支持CPU/GPU (CUDA)两种类型 | GPU (CUDA) |
| CPU | 选择CPU资源时可设置,可以设置CPU计算的线程数 | |
| Executable Settings | 配置客户端执行文件目录 | D:/Program Files/SimWorks/SimWorks FD Solutions/bin |
| GPU - 1 Devices | 在选择GPU资源时,用户可根据实际需求勾选对应的GPU设备ID进行计算;若希望使用全部GPU资源,也可点击All GPU Devices按钮一键启用。界面中显示的GPU参数依次为:设备ID、名称、显存容量、显存带宽、计算能力、SM核心数以及是否支持TCC模式。 | GPU 0 |
| Preview - test command | 实时显示资源测试命令 |
文件存储 #
使用Local资源的工程由用户选择文件路径进行保存,相关扫描以及优化工程将自动保存在对应文件目录下。

Remote资源 #
Remote 资源基于用户自建的服务器基础设施,构建多主机计算环境,实现多节点并行计算。该模式直接利用用户现有的服务器资源,具备良好的扩展性,可根据仿真需求灵活部署计算节点,适用于需要跨节点资源共享与团队协作的企业或科研机构。
MPI环境配置 #
使用 Remote 资源时,用户需在各计算节点上配置相同的 MPI 环境,同时确保以下条件:
- 所有远程节点安装并配置相同版本的 MPI;
- 使用相同的本地账号登录各节点;
- 将软件安装在各节点的相同路径下;
- 若使用 CUDA-aware 的 Open MPI,确保 GPU 驱动和 CUDA 版本兼容。
当前 SimWorks 支持以下主流 MPI,可以参考MPI环境配置页面进行具体的配置操作。
- Open MPI(适用于Linux和macOS):Open MPI是一个开源的、高性能的MPI,支持 CUDA-aware 功能,可显著降低跨节点显存交换延迟,提升多节点多 GPU 架构下的 FDTD 仿真效率。
- Intel MPI(适用于 Windows、Linux和macOS):英特尔公司开发的高性能MPI,针对英特尔硬件和网络进行了优化,提供高性能的多节点通信。
- Microsoft MPI(适用于Windows系统):微软官方开发的MPI,主要针对Windows平台进行优化。
用户需从对应的 MPI 官方网站下载并安装相关软件,具体链接可在MPI友情链接中找到。在Remote资源配置完成后,建议使用 Resource Test 功能测试Remote资源的可用性。
Remote资源设置 #
无论使用何种MPI,均需要用户主动设置mpi host,选择对应的算力资源,多个算力资源的主机名称之间用英文逗号分隔。CPU算力资源支持设置每个主机中的进程数、线程数,GPU算力资源支持选择每个主机所拥有的GPU资源(GPU ID之间使用英文逗号分隔)。
- CPU算力资源设置
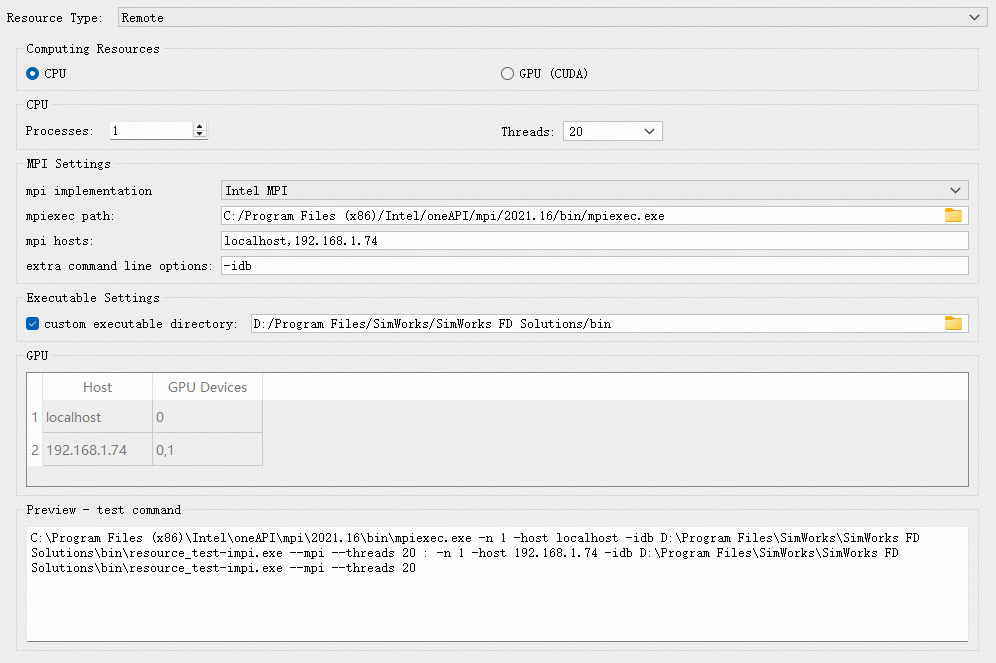
- GPU算力资源设置
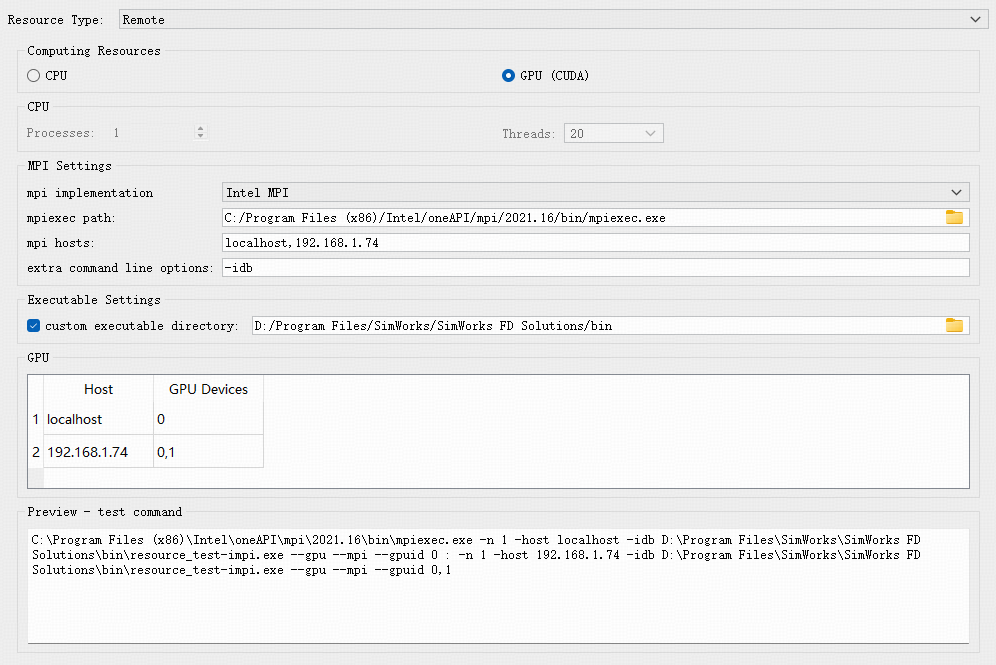
以上各选项意义如下:
| Name | Description | Example |
|---|---|---|
| Computing Resources | 算力类型选择,支持CPU/GPU(CUDA)两种类型 | GPU (CUDA) |
| CPU | 选择CPU算力时可设置,可以设置每个主机CPU资源计算的进程数以及线程数 | |
| MPI Settings | MPI设置。 MPI implementation :选择MPI类型,软件支持Open MPI、Intel MPI以及Microsoft MPI三种MPI类型,不同操作系统支持类型不同。 Mpiexec path :设置自定义MPI执行文件目录。 Mpi hosts :配置多个MPI主机列表。 Extra command line options :自定义命令行参数(部分mpiexec需要额外的参数)。 | "Intel MPI" "C:/Program Files (x86)/Intel/oneAPI/mpi/2021.16/bin/mpiexec.exe" "127.0.0.1,192.168.1.74" "-idb" |
| Executable Settings | 配置客户端执行文件目录 | D:/Program Files/SimWorks/SimWorks FD Solutions/bin |
| GPU | 在选择GPU算力时可选,设置每个MPI主机所使用的GPU资源,当该主机拥有多个GPU资源时,GPU ID使用英文逗号进行分隔 | "127.0.0.1: 0" "192.168.1.74: 0,1" |
| Preview - test command | 实时显示资源测试命令 |
文件存储 #
使用Remote资源的工程同样由用户选择文件路径进行保存,相关扫描以及优化工程也将自动保存在对应文件目录下。
Slurm 集群资源 #
Slurm 集群资源 是一种基于 Slurm (Simple Linux Utility for Resource Management)作业调度系统的计算资源,允许用户利用已有的 Slurm 集群进行仿真计算。Slurm 是一种开源的作业调度系统,广泛应用于高性能计算集群中,能够有效地管理和调度计算资源。该模式适用于已经搭建了 Slurm 集群的企业或科研机构,可充分利用现有集群资源进行仿真计算。
Slurm 集群资源具备以下功能特点:
- 自动化任务流 :提交任务后自动传输文件、同步进度,计算完成后回传结果,操作体验与本地一致。
- 资源优化调度 :支持基于网络拓扑的任务分配,优化通信密集型仿真效率。
- 扩展性强 :用户可根据仿真需求灵活部署计算节点,适用于跨节点资源共享及团队协作场景。
- 共享文件夹传输 :支持通过共享文件夹传输文件,实现工程文件及结果数据的直接读写,无需通过传统的 SSH+SCP 方式进行上传和下载。
- 本地任务提交 :允许在本地直接发起 Slurm 任务(仅 Linux 系统),通过在本地直接运行 sbatch 等 Slurm 命令来提交计算任务,无需通过 SSH 连接到远程管理节点。
注意事项 :使用共享目录传输文件时,需确保本地与集群路径权限一致。
Slurm 集群资源配置 #
使用 Slurm 集群资源时,用户需要进行以下配置:
- 设置集群的基本信息
- 选择集群类型为Slurm,并设置共享工作目录
- 任务提交方式
- 选择任务提交方式:Local(本地提交,仅Linux系统支持)或 Remote(SSH)(远程SSH提交)。选择后一种方式时,需要配置节点的主机名或IP、端口、用户名和SSH密钥文件。
- 文件传输方式
- 选择文件传输方式:Shared directory(共享目录)或 SCP(通过 SSH + SCP 上传下载文件)。选择共享目录时需要配置与提交方式 Local 或 Remote(SSH) 路径的映射关系。
- 作业资源配置
- 设置任务进程数以及提交命令,支持定义自定义 Slurm 参数。
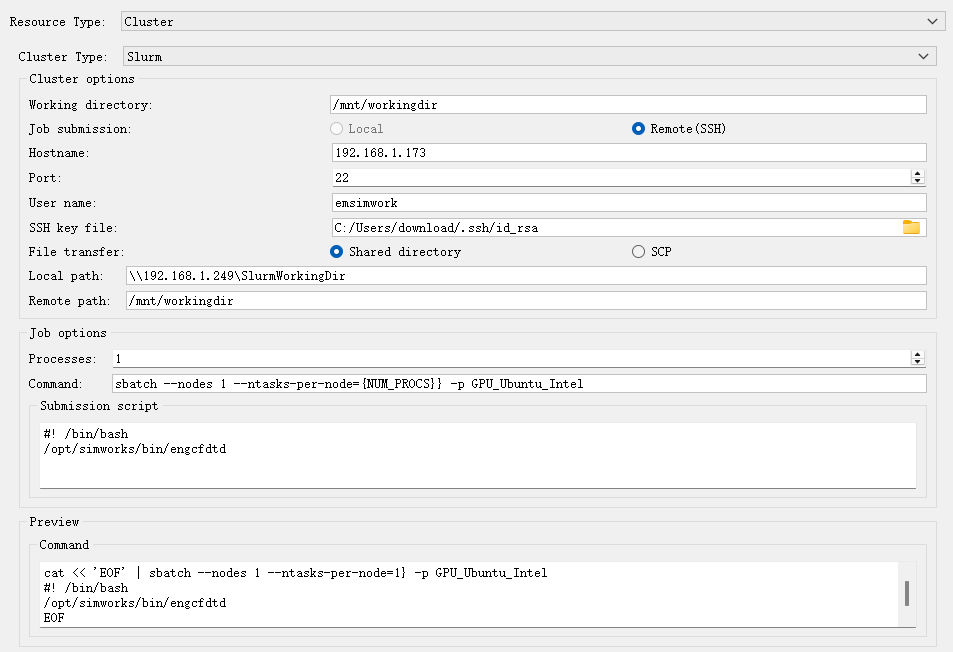
页面具体选项含义如下:
| Name | Description | Example | |
|---|---|---|---|
| Cluster Type | 选择集群类型,当前仅支持Slurm 。 | ||
| Cluster options | Working directory | 集群共享工作目录,需所有节点可访问。 | 路径需绝对路径或$HOME/开头,如/mnt/workingdir。 |
| Job submission | 提交方式:Local(本地提交)或 Remote(SSH)(远程 SSH 提交)。 | Local 模式仅支持 Linux 系统,需安装 Slurm 客户端。 | |
| Hostname/Port/User name | 远程提交时需填写管理节点IP/主机名、SSH端口、用户名。 | slurmtest、22、user |
|
| SSH key file | SSH密钥文件路径,用于免密登录管理节点。 | C/User/download/.ssh/id_rsa |
|
| File transfer | 传输方式。可以选择Shared directory(共享目录)或 SCP(SSH+SCP) | ||
| Job options | Processes | 任务进程数,需与集群资源匹配。 | 如设置为1,对应命令sbatch --nodes 1 --ntasks-per-node 1。 |
| Command | 任务命令,支持自定义Slurm参数,需包含资源请求标志,否则任务可能失败。 | --cpu-per-task、--gpus-per-node |
|
| Preview | command | 实时显示资源测试命令,验证配置正确性。 |
Slurm 集群通常包含 1 个管理节点和多个计算节点,需通过 slurm.conf 配置节点资源及调度策略。管理节点负责任务调度,计算节点提供算力支持;任务提交支持 Local(本地直接运行 sbatch 命令,需安装 Slurm 客户端)和 Remote(SSH)(通过 SSH 连接管理节点提交任务)两种方式,文件传输可采用 Shared directory(本地与集群共享目录映射)或 SCP(通过 SSH+SCP 上传下载文件)方式;完成配置后,用户可在高性能计算集群上无缝执行仿真任务,仅需发起"运行"指令,软件自动将任务提交至调度队列并传输输入文件,任务管理器持续同步状态与进度,计算完成后结果数据自动回传,实现端到端的自动化工作流集成。
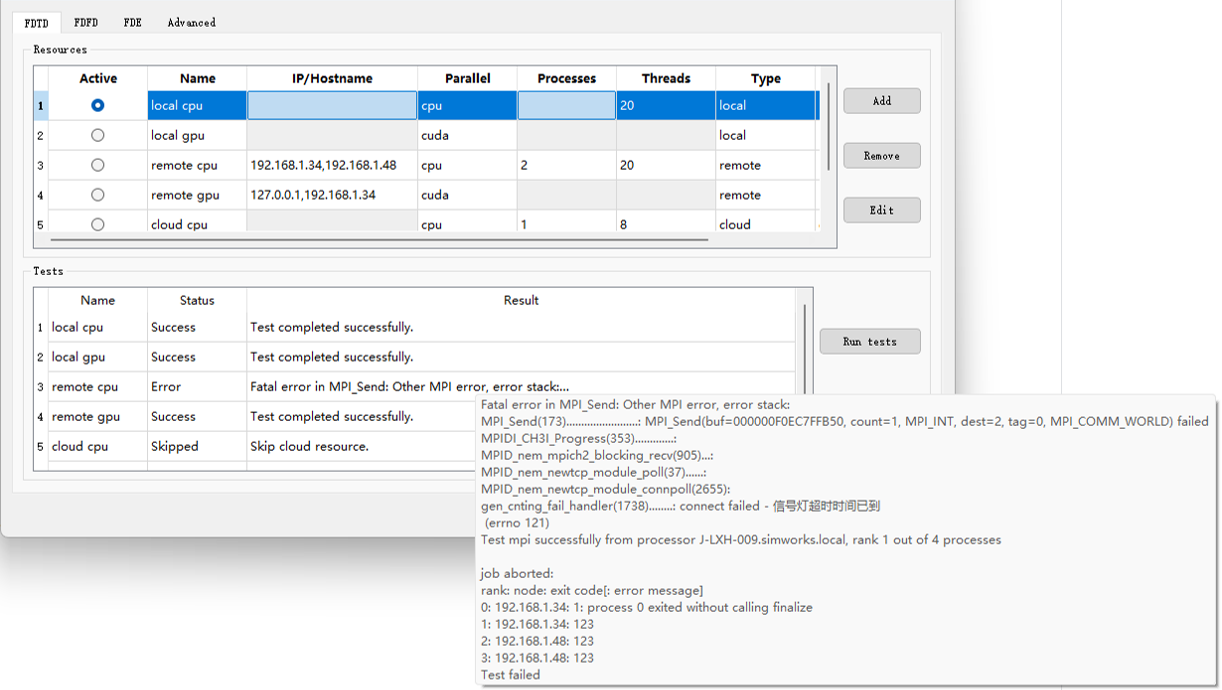
Resource Test #
对于Cloud资源,Resource Test功能默认不启用,软件会直接跳过该测试过程。
Resource Test功能主要对Local以及Remote所配置资源的MPI与CUDA环境进行测试。资源配置完成后,点击Run tests按钮,系统会依次对已配置资源进行测试,并显示该资源是否能正常运行。在测试过程中,可以点击Stop tests停止测试。
测试完成后,测试成功在Result中显示Test completed successfully,如若测试失败,鼠标悬浮于Result列对应单元格内会显示具体失败原因,如下图。
高级 #
Advanced标签页用于设置计算机资源的计算精度,Precision Setting用于设置计算机资源的计算精度。下图为完整版客户端Advanced标签页。
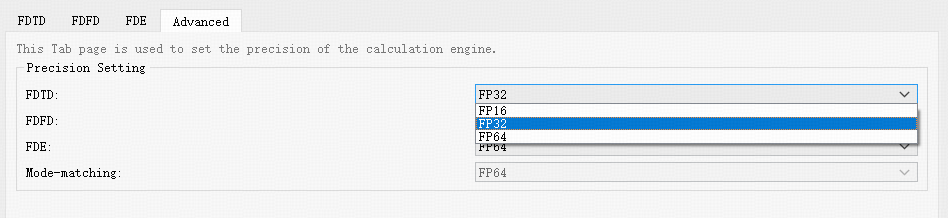
| Name | Description |
|---|---|
| FDTD | 下拉选择FP16(半精度)、FP32(单精度)或FP64(双精度)。 |
| FDFD | 下拉选择FP32(单精度)或FP64(双精度)。 |
| FDE | 下拉选择FP32(单精度)或FP64(双精度)。 |
| Mode-matching | 默认为FP64(双精度),只读参数。 |
当FDTD求解器在NVIDIA GPU上运行时,支持使用FP16(半精度)计算。相比于FP32(单精度),FP16可显著减少显存占用并提升计算效率。
具体FP16算力请查阅您的GPU型号相关资料,如当前GPU不支持FP16计算或FP16计算速度较慢,则不建议使用FP16进行计算。例如,在NVIDIA Tesla V100上,FP16的理论计算能力约为FP32的两倍。在实际SimWorks仿真中的对比如下所示:
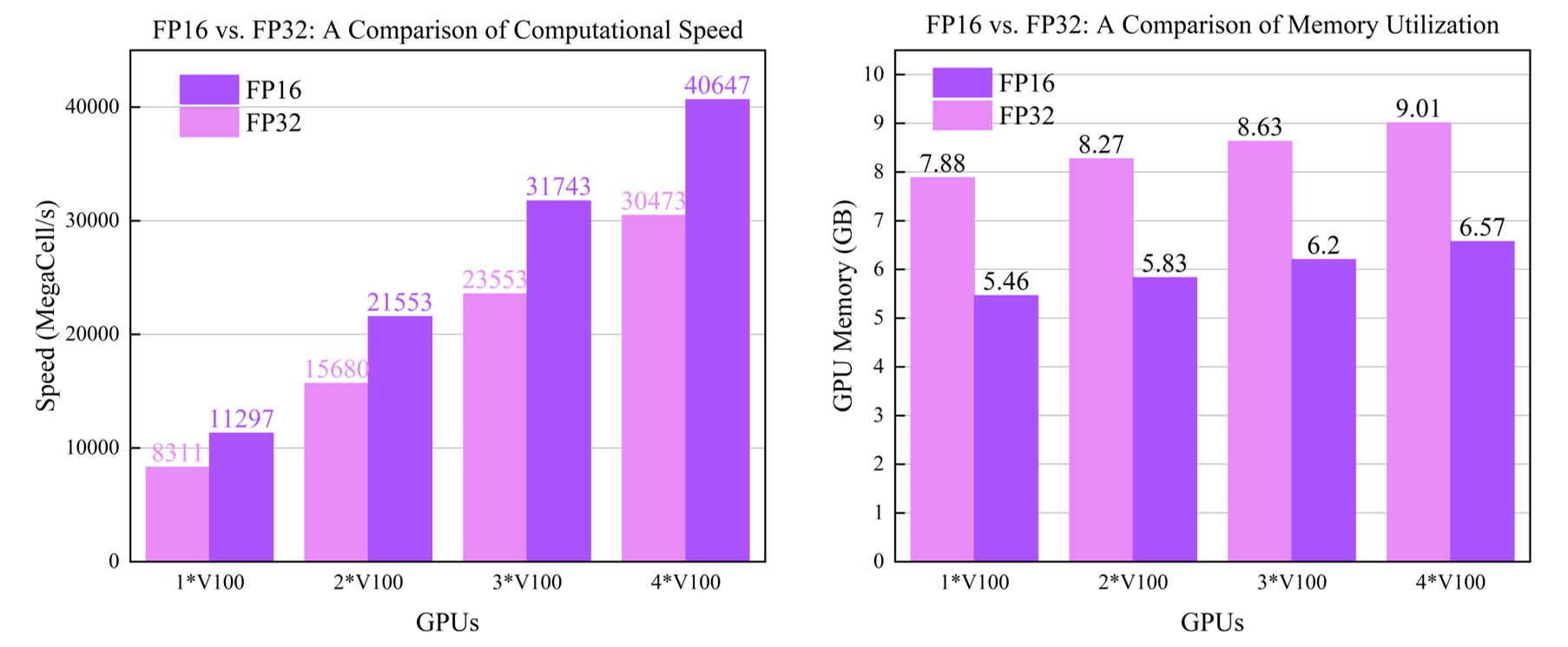
FP16适用范围与注意事项:
-
FP16支持介质和色散材料仿真,尤其在对精度要求不高且仿真耗时较长的任务中优势明显。
-
FP16数值范围有限(±6.5×104),不适用于能量极大或光源振幅远大于1的场景(如非线性光学仿真),以避免数值溢出导致的仿真发散。
-
FP16的有效精度为0.00097,对数值精度敏感的工程(如谐振器)需谨慎使用,防止数值下溢引起结果的不稳定。对于其他仿真时间较长的工程中,建议将提前截止率设置为 5×10−5 以平衡效率与精度。
-
软件中针对色散材料使用的 VP-EP 1 共形网格划分暂不支持FP16计算。
-
在以下情况中,使用FP16可能导致计算错误,目前不建议用户使用:
- 使用Bloch周期边界等涉及复数场的FDTD仿真;
- 2D材料(如石墨烯、RLC材料)或TFSF光源跨越不同材料的仿真。
MPI #
使用MPI可以把FDTD计算区域分为几份,每个进程负责一个计算区域。MPI负责多进程之间的通信。目前仅在使用Remote资源时需要进行配置MPI环境,该资源的正常使用需要用户正确配置本地电脑的MPI环境。
GPU和CPU #
本部分主要介绍CPU和GPU两种处理器的差异,用户可根据实际仿真需求选择合适的运算资源。
- GPU拥有较多的核心,而CPU的核心较少。但GPU每个核心的计算能力低于CPU;
- CPU擅长逻辑处理,适合顺序和复杂决策任务。GPU擅长并行处理,适合大量浮点运算;
- CPU一般用于执行系统和应用程序,而GPU则多用于渲染图形和图像。CPU更适合运行复杂的数据处理和逻辑操作,而GPU更适合运行大量简单的数学计算。